
大型语言模型 (LLM) 安全风险、案例与防御策略
- 作者: bayuncao
- 收录:
- 简介:
这是 ChaMD5 安全团队 AI 组的第一篇关于大语言模型(LLM)的安全研究报告,尽管团队在 AI 安全领域已经有了一定的积累, 但由于是初次撰写报告, 我们深知在专业性与严谨性方面可能存在着诸多不足。真诚地希望各位读者老师能够不吝赐教,对报告中的任何问题提出宝贵的意见与建议,帮助我们不断改进与提升。 1. 引言 2. LLM 安全格局:机遇与风险并存 3. 剖析核心风险:OWASP

大模型安全风险治理与防护
- 作者: demonbinli
- 收录:
- 简介:
大模型企业应用十大常见安全风险 01 样本投毒(数据污染) 02 恶意利用(Prompt注入攻击) 03 代码辅助工具数据泄露(第三方代码辅助工具) 04 第三方代码依赖风险(开源模型/库污染) 05 自动化Agent权限滥用 06 自建模型平台暴露面过大 07 训练数据隐私泄露 08 模型推理劫持(对抗样本攻击) 09 AI伦理与偏见放大 10 开源模型滥用(深度伪造与辅助犯
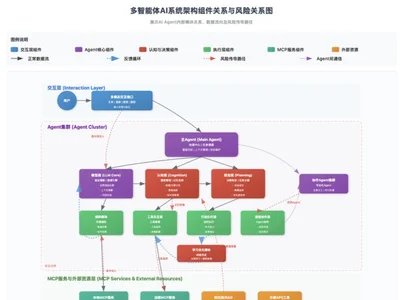
大模型和多智能体系统安全风险分析和洞察
- 作者: [email protected]
- 收录:
- 简介:
随着⼈⼯智能(AI)技术的⻜速发展,以⼤型语⾔模型(LLMs)为核⼼的智能体(AI Agents)和多智能体系统(Multi-Agents System)正⽇益深⼊到各个应⽤领域,从简单的对话助⼿到复杂的⾃主决策系统。与此同时,作为连接 AI 模型与外部世界(包括⼯具、数据源和其他智能体)的关键桥梁,模型上下⽂协议(MCP)的出现进⼀步拓展了 AI 智能体的能⼒边界。然⽽,这种能⼒和集成度的提升也